
Figure 1: input tokens
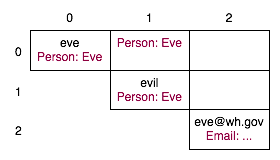
Figure 2: parsing in progress
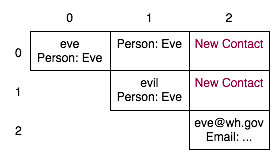
Figure 3: parsing complete
by Max Goldman and Robin Stewart
May 18, 2007
Final Project for 6.863: NLP
In the Haystack group at MIT CSAIL there is an ongoing research project focused on creating a tool called "Jourknow" (pronounced "jour-no"). One of the aims of Jourknow is to provide a convenient place to capture bits of information and later retrieve them. Some of these notes are bound to be incomprehensible to anyone other than the note-taker, let alone a computer system, but many of the notes have a structure that could be recognized by computer and automatically stored in a structured way for easy retrieval later. For example, if you type "meeting with karger at 3pm in G531", the system would ideally be able to recognize this as an event with start time 3pm today, location 32-G531, and with Prof. David Karger. It could then place the event in a system-wide calendar server so that it would be viewable on your calendar and by reminder services. The advantage of this free-text input interface is that it is flexible and often much faster than navigating through a graphical user interface to find the desired structured input form (e.g. "create new event") and then entering the properties separately.
Google's calendar service can do this type of parsing in the meetings domain, but we would like to go far beyond this to create a system that is:
Building our system on top of semantic web technologies allows us to support both goals. The generality of these technologies allows us to create and reuse ontologies for any domain, arbitrarily extending the system's capacity. And if personal/local information is encoded in semantic-web-readable form (RDF), the system can easily access and interpret that information.
In this project we implemented a system that reads in specified domain ontologies based on the RDF, RDFS, and OWL standards and uses them to construct customized "pidgin language" parsers. To increase the generality of the pidgin language, we introduce two new RDF properties, "surface" and "preposition", which allow ontology writers to specify the natural language realizations of their ontology concepts.
The system is implemented in Python, requiring features from version 2.5. The following Python packages are also required:
A package containing all of our source code and configured to reference the example ontologies and entities used during our testing is available here:
Start the interactive front-end to the parser by running:
python interactive.py
After printing some debug information about the state of the parsing "agent," the system will be ready to accept input at the prompt. Type "exit" or use Ctrl-C to quit.
When the system succeeds in recognizing some input, it outputs the results in a format described in Section 4.
Rather than have either the ontology authors or users specify a grammar for legal pidgin phrases, in our approach we use the information already available from the semantic web ontologies to determine phrase structure and meaning.
Most aspects of the parsing system are order-agnostic: phrases such as "meet Bob tomorrow 4pm," "4pm tomorrow meet Bob," and "Bob 4pm tomorrow meeting" parse equally well and have identical meaning. The user is given the flexibility to keep his own organization and mental model (is he thinking primarily by task, by time, by person, etc.), entering phrases in the language most meaningful to him.
Instead of relying on ordered grammar productions to drive parsing, the system is instead type-driven. Potential parses of words or phrases from the input have type information, and this type information is used by other parsers to determine how they can parse larger parts of the input. In the "meet Bob tomorrow 4pm" example, the token "Bob" is parsed from a token of type string into a person token that refers to someone named Bob. Later in the parsing process, a parser that requires a token of type person can now consume "Bob." This strategy corresponds to the intuitive human method of parsing these pidgin phrases: we know that Bob is a person, tomorrow at 4pm is a time, and so forth, and we know how those types of elements can be brought together to form a higher-level semantic entity—a meeting—even if the word "meeting" was not mentioned.
The type-driven parsers used by the system comes from two sources. Some are defined manually, recognizing simple entities such as dates and email addresses by regular expression matching. These parsers consume string tokens and offer up tokens of some semantic type. The domain ontologies provide the second set of parsers. Each ontology has a parser for manipulating entities of the type defined by it, and these parsers are identical in operation, running a generalized algorithm that finds parses based on the ontology contents.
All parsers assign weights to the possible parses they generate, and these weights are used to resolve ambiguity. As the number of ontologies and entities grows, weights become increasingly important for finding the most likely parse of an under-constrained input. Weights are combined multiplicatively, so that a parse relying on low-probability parses of constituent tokens will itself have low probability.
We wrote several ontologies to support the implementation:
The first ontology, nl.n3, is what you might call a meta-ontology, which defines properties that are used to define the natural language realization of any ontology concepts. These properties are intended to be used to augment existing third-party ontologies so that our natural language parser has an easier time of understanding the concepts they describe. The "surface" property lets the ontology writer specify words that describe a class; for example, a meeting object may be described with the word "meeting" or "meet", or maybe even "talk". The "prep" property lets the ontology writer specify words that prefix object properties. For example, "with" may be used as a preposition preceding the meeting attendee. So "meeting with karger" gets recognized as a class surface, followed by a property preposition, followed by a person specifier.
The rest of the ontologies are examples of types of structured information that the system can be told to parse.
Finally, we created some sample knowledge bases containing a few examples of people and places. These comprise the knowledge which the person and place recognizers can match against. The files are at "entities/people.n3" and "entities/places.n3". An example entity is:
<#ProfKarger>
rdf:type person:Person ;
person:fullname "David Karger" ;
.
Some entities are easily recognized by regular expressions but do not lend themselves well to the framework of semantic web triples. Thus we implemented two special recognizers that use regular expressions in order to recognize dates/times and email addresses.
The recognizer for dates and times is built using the "parsedatetime" open-source date-time recognizer (Taylor & Chhajed 2007). If the parsedatetime system can find a date and/or a time somewhere in the current list of string tokens, it returns a flag corresponding to date, time, both, or none. However, we don't want this parser to consume longer strings, such as "with karger at 4pm", so our implementation rejects if either the start word or end word does not contain date/time information. In the example, "with" has no date/time info so the phrase will be rejected. However, in "4pm tomorrow", both the start and end word contain date or time information. The returned token is given weight: 1/(length of phrase).
The email address recognizer is much simpler; it only accepts a single string token, which it tries to match against two regular expressions. The first, '[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.[a-z]{3}', matches against a full email address such as "karger@mit.edu". If the match is successful, the recognizer returns a new token of Email type with weight 1. The second regular expression, '[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+', matches against the shorthand version of email addresses, e.g. "berwick@mit". A match against this returns and Email token with weight 0.8.
3.4.1 Existing entity recognizer
Existing semantic entities are recognized by referring to one of their properties, and matching is currently done by checking for substrings. Thus, "karger," "david," "dav kar," and "david k" could all refer to the person named "David Karger." Such parses are assigned a weight proportional to the amount of the string matched (reflecting increased confidence from additional information), but could be improved with data about which entities are more important to the user or how the user frequently refers to particular entities.
"Surface" names for the entity type and "prepositions" for its properties are also admitted by the entity recognizer, so that "person named david k" is parsed.
3.4.2 Entity creation recognizer
Commands to create new entities, such as "Karger 4pm Kiva," are parsed by relying on type information. The parser looks for available tokens of the required types, fitting them into slots based on type and "preposition" information. An entity creation parse is promoted as a possibility only when all the required properties of such an entity have been filled in. So with "Karger 4pm Kiva," the parser relies on the work of previous typed recognizers that handled the identification of each token as a known person, time, and place, respectively, and consumes those tokens by filling them into the attendee, start time, and location properties of a new meeting.
Since "preposition" information is also used, the system could be extended, by means of only a new ontology, to handle entities with multiple properties of the same type. For example, a meeting with both start time and end time would be parsed correctly from the phrase "Karger Kiva start 4pm end 6pm." The system also allows "surface" forms to appear in the phrase at any location, so both "meet Karger 4pm Kiva" and "Kiva 4pm meeting Karger" are valid.
The range of properties examined by the entity-finding- and required by the entity-creating-parsers is restricted by a configuration file that constrains the system's "model" of semantic types to a subset of their properties. This is done to ease interoperability with existing ontologies that may specify many tens of uninteresting properties.
Figure 1: input tokens
Figure 2: parsing in progress
Figure 3: parsing complete
The parsing algorithm we have implemented in this preliminary version of the system uses all parsers to examine all subsequences of tokens until no parser is able to offer a new potential parse. Recognition of the input phrase is considered successful if there is a parse spanning the entire input; otherwise, the attempt is considered a failure.
Our algorithm is implemented with a data structure from chart parsing. A triangular matrix of cells stores input tokens and output parses that span the range of tokens indicated by their indices.
Figure 1 shows the contents of the chart after receiving the input "eve evil eve@wh.gov," which we understand to be a request to create a new contact entity that maps the person Eve Evil in our datastore of people to the email address eve@wh.gov. Each of these tokens in the chart is of type string.
After running the person semantic web recognizer and the email regular expression recognizer, new tokens have been added to the chart (Figure 2). The person token in cell (0,0) indicates that input "eve" could refer to Eve Evil; the person token in cell (0,1) indicates that "eve evil" together also could refer to Eve. Since short names could refer to many entries of different types in our datastore, all possible parses are recorded. We also record all parses so that we never commit to a particular strategy for consuming any given token until we reach the final stage, and choose an overall parse.
Finally, running the contact creation recognizer adds two new tokens to the chart, shown in Figure 3. In both cases, the new token is a parse that consumes the person to its left and the email address below. The token in (0,2) spans the entire input, and is therefore correctly returned by the system as the best parse for this phrase.
We evaluated the system by testing the variety of input forms it can recognize, given the provided domain ontologies. We currently import the person, place, meeting, and contact info ontologies, and provide sample knowledge bases containing known people and places. With this, the system can recognize a vast range of input sentences, such as:
meeting with karger at 4pm in g531
tomorrow 4pm in g531 meeting with karger
karger 4pm tomorrow g531
g531 4pm karger
meet robin at au bon pain noon thursday
Meet someone named Max somewhere called Kiva at 3:30
karger@mit.edu david karger
david karger email karger@mit.edu
In all cases listed above, the parser recognizes the correct meanings. For example, the first sentence, "meeting with karger at 4pm in g531", is interpreted as:
0.28125 CREATE A NEW http://people.csail.mit.edu/stewart/meeting.n3#Meeting
Dictionary
http://people.csail.mit.edu/stewart/meeting.n3#dtstart:
(2007, 5, 20, 16, 0, 0, 6, 140, 1)
http://www.w3.org/1999/02/22-rdf-syntax-ns#type:
http://people.csail.mit.edu/stewart/meeting.n3#Meeting
http://people.csail.mit.edu/stewart/meeting.n3#location:
file:///6863repository/entities/places.n3#32-G531
http://people.csail.mit.edu/stewart/meeting.n3#attendee:
file:///6863repository/entities/people.n3#ProfKarger
In other words, the system, with total weight 0.28125, decided to create a new object of type "Meeting" as defined in the "meeting.n3" ontology. It populates the "dtstart" field with a recognized date (May 20, 2007 at exactly 4pm). Its own "type" is "Meeting" as stated earlier. It found a location, "32-G531" in the local datastore "places.n3" and uses it to populate the "location" field. Finally, it matched a person referred to as "ProfKarger" in the local datastore "people.n3" and uses that to populate the "attendee" field.
The idea is that this information can be used downstream to actually update a calendar event server, which can then be browsed in a hierarchical or faceted manner—for example, to view all upcoming meetings with ProfKarger. This sort of browsing is possible because the parser was able to match a particular person, not just a generic "person" type.
Although the present system serves as a convincing proof-of-concept, significant future work remains to make the system usable in a realistic setting. From an implementation standpoint, the current check-all-parses algorithm has poor asymptotic complexity and would benefit greatly from heuristics that focus the system's parsing efforts on building parses that will eventually span all input tokens.
In order for this system to be useful in practice, the datastore must be updated by the system in response to commands to create a new meeting, contact, etc. Currently, the datastore is not updated in this way. Furthermore, we have not yet implemented parsing of phrases that should update the properties of an existing entity, such as "4pm meeting moved to 5pm."
Another ambitious direction for future work is the development of a discourse model, in which previously mentioned items or outside information about e.g. the current time or location of the user provide a frame for interpreting pidgin phrases. With such a framing system, one could imagine entering the phrase "meetings tomorrow" followed by "4pm Alice" and "5pm Bob," and the system would schedule the appropriate two meetings in the user's office or usual meeting place. We believe that the present parsing strategy will extend cleanly to handle all of these features.
Many thanks to Max Van Kleek and Professors David Karger and Robert Berwick for several discussions about this project. Thanks also to Greg Little, who offered suggestions from his experience parsing "keyword commands."
Taylor, M and Chhajed, D. (2007) "parsedatetime project" <http://code-bear.com/code/parsedatetime/>
Van Kleek, M., Bernstein, M., Karger, D. and schraefel, m. c. (2007) GUI— Phooey! : The Case for Text Input. Submitted to UIST 2007, Rhode Island.